
개요
코틀린에서 비동기 처리를 위해 내놓은 코루틴에 대한 글은 저번에 정리해봤다!
오늘은 Coroutine Flow에 대해 정리해보고, 어떤게 있는지 알아가보자
Flow가 나온 이유?
이 부분이 제일 의문이였다. 코루틴을 사용하면 되는데 Flow가 나온 이유가 뭘까. 글을 정리하다 보니 알게 되었다.
코루틴의 suspend 함수는 비동기로 처리해주지만 값을 하나만 return 해준다. 이러한 문제점을 해결하고자 비동기 스트림 API Flow가 등장하게 된다. Flow는 지속적으로 나오는 여러 개의 데이터를 처리하는데 유용하다고 한다.
또한 다양한 연산자를 바탕으로 데이터 변환, 결합, 예외 처리 등을 손쉽게 수행할 수 있다고 한다.
Flow의 기본 개념
Flow는 데이터의 방출(emit)과 수집(collect)를 기반으로 동작한다. 데이터를 하나씩 방출하고, 소비자가 데이터를 소비할 때마다 데이터를 순차적으로 처리합니다.
여기서 Cold Stream과 Hot Stream의 개념이 등장하는데 다음과 같이 정리할 수 있다.
Cold Stream
- 하나의 소비자에게 데이터를 발행한다.
- 소비자가 소비를 시작 할 때 데이터를 생성한다.
- 소비를 시작하기 전에는 동작하지 않기 때문에, 메모리도 필요할 때 사용하게 된다.
- 모든 데이터가 스트림 내부에서 생성된다.
- Flow, Rx Java의 Observable
Hot Stream
- 여러 소비자에게 데이터를 발행한다.
- 소비자가 데이터에 접근하지 않더라도 계속 데이터를 발행한다.
- 모든 데이터는 스트림 외부에서 생성된다.
- LiveData, Rx Java의 Subject
이렇게 정리할 수 있는데 예를 들면, Cold Stream은 CD 플레이어, Hot Stream은 라디오에 비유할 수 있다.
CD 플레이어의 경우 한 명의 소비자가 사용하고, 플레이어 중단시 재생이 되지 않는다. 그리고 언제든지 재생하는 시점에 동일한 음악을 제공받게 된다.
라디오는 여러 소비자가 사용하고, 방송을 듣지 않더라도 계속해서 방송하기 때문에 소비자가 라디오를 듣는 시점에 따라 내용이 달라지게 된다.
즉, Flow는 Cold Stream으로 데이터를 소비하는 소비자에서 collect()연산자를 통해 순차적으로 데이터를 받아올 수 있는 것이다.
collect()만 coroutine 블록에서 실행되면 된다.
하지만 주의할점이, Flow의 모든 API가 다 Cold Stream은 아니고 Hot Stream도 존재한다.
Flow 예제
아래 코드는 Flow를 생성하고 수집하는 간단한 코드인데 1부터 5까지의 숫자를 emit()을 통해 순차적으로 방출하고 collect()를 통해 수집하여 출력한다. 이때 첫 번째 플로우가 수집을 완료 한 뒤, 두 번째 Flow의 수집이 시작된다.
import kotlinx.coroutines.flow.*
import kotlinx.coroutines.runBlocking
fun simpleFlow(): Flow<Int> = flow {
for (i in 1..5) {
emit(i) // 값을 하나씩 방출
}
}
fun main() = runBlocking {
simpleFlow().collect { value ->
println("첫 번째 $value")
}
simpleFlow().collect { value ->
println("두 번째 $value")
}
}
// <출력>
// 첫 번째 1
// 첫 번째 2
// 첫 번째 3
// 첫 번째 4
// 첫 번째 5
// 두 번째 1
// 두 번째 2
// 두 번째 3
// 두 번째 4
// 두 번째 5Flow 생성 및 수집
Flow 생성
Flow를 생성하는 방법은 여러가지가 있는데 그 방법들을 하나씩 살펴보자.
1) flow 빌더
사용자 정의 Flow를 생성할 때 사용한다.
fun numberFlow() : Flow<Int> = flow{
for(i in 1..3){
delay(100)
emit(i)
}
}
2) flowOf 빌더
정해진 값들을 내부적으로 반복문을 돌려 emit 해준다.

flowOf(1,2,3,4)
.collect{ number ->
println(number)
}
3) asFlow 빌더
컬렉션이나 시퀀스를 Flow로 바로 변환해주는 함수이다.
내부적으로 forEach를 활용해 emit을 진행한다.
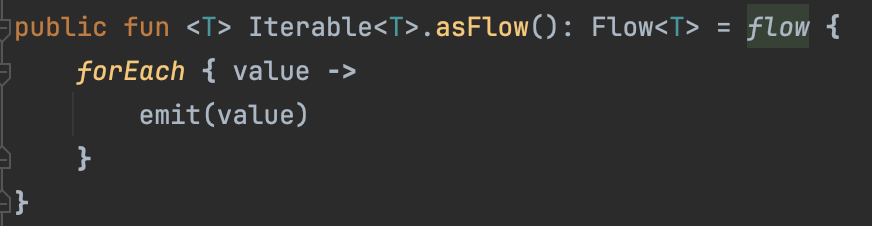
val list = listOf("A", "B", "C")
val flowFromList: Flow<String> = list.asFlow()
수집
1) collect
Flow의 모든 값을 수집하고 처리한다.
fun main() = runBlocking {
numberFlow().collect { value ->
println("Collected: $value")
}
}
// <출력>
// Collected : 1
// Collected : 2
// Collected : 3
2) collectLatest
이전의 처리가 완료되지 않은 값에 경우 취소하고 최신의 데이터만 처리해준다.
주의 점은, 첫 번째 데이터가 나오는 도중 2번째 데이터가 나오게 되면, 첫번째 데이터를 cancel 시켜버린다.
fun main() = runBlocking {
flowOf(1,2,3,4)
.collectLatest { value ->
println("Collected latest: $value")
delay(200) // 이전 값의 처리를 취소하고 최신 값만 처리
println("Done $value")
}
}
// <출력>
// Collected latest : 1
// Collected latest : 2
// Collected latest : 3
// Collected latest : 4
// Done 4
200의 delay가 발생하는 동안 2, 3, 4가 나오는데 그 동안 2, 3은 취소되고 Done으로 4가 찍히게 된다.
3) collectIndexed
인덱스와 함께 값을 수집하는 것.
fun main() = runBlocking {
flowOf(1,2,3,4).collectIndexed { index, value ->
println("Index $index: $value")
}
}
// <출력>
// Index 0 : 1
// Index 1 : 2
// Index 2 : 3
// Index 3 : 4
Flow 연산자
Flow는 위에서도 언급했다시피 다양한 연산자를 제공해 데이터를 변환, 필터링, 결합하는 등의 작업을 쉽게 수행할 수 있다. 이때 연산자는 중간 연산자와 최종 연산자로 나눌 수 있다고 한다.
중간 연산자
1) map
흘러나오는 데이터를 변경 할 때, map 연산자를 사용한다.
fun transformedFlow(): Flow<String> = flow {
val data = listOf("Kotlin", "Coroutines", "Flow")
data.forEach {
emit(it)
}
}.map { it.uppercase() }
fun main() = runBlocking{
transformedFlow.collect{ data ->
println(data)
}
}
// <출력>
// KOTLIN
// COROUTINES
// FLOW
2) filter & filterNot
filter → 조건에 맞는 데이터만 흘러나가도록 하는 코드이다.
filterNot → 조건에 맞지 않는 데이터만 흘러나가도록 하는 코드
fun filteredFlow(): Flow<String> = flow {
val data = listOf("Kotlin","Java", "Flow")
data.forEach {
emit(it)
}
}.filter { it.contains("o") }
fun main() = runBlocking{
filteredFlow().collect{ data ->
println(data)
}
}
// <출력>
// KOTLIN
// FLOW
3) transform
들어오는 데이터를 변형시키거나, skip도 가능하고 같은 데이터에 대해 다른 형태로 여러 번 보낼 수도 있다. 그래서 map이나 filter와 같은 기존의 중간 연산자보다 더 복잡한 변환 작업을 수행할 때 유용하게 사용된다.
fun main() = runBlocking{
val numberFlow = flow {
for (i in 1..3) {
delay(100)
emit(i)
}
}
numberFlow
.transform { number ->
emit("숫자 $number 방출됨")
emit("숫자 ${number}의 제곱은 ${number * number}입니다")
}
.collect { transformedValue ->
println(transformedValue)
}
}
// <출력>
// 숫자 1 방출됨
// 숫자 1의 제곱은 1입니다
// 숫자 2 방출됨
// 숫자 2의 제곱은 4입니다
// 숫자 3 방출됨
// 숫자 3의 제곱은 9입니다
4) take
몇개의 데이터만 수집할지 결정해 주는 연산자이다.
fun main() = runBlocking {
(1..6).asFlow()
.take(2)
.collect { number ->
println(number)
}
}
// <출력>
// 1
// 2
5) drop
몇 개의 데이터를 drop 한 뒤에 데이터만 소비한다.
fun main() = runBlocking {
(1..6).asFlow()
.drop(2)
.collect { number ->
println(number)
}
}
// <출력>
// 3
// 4
// 5
// 6
종단 연산자
Flow의 데이터를 수집하거나 결과를 반환하는 역할을 한다. 최종 연산자에서는 Flow 스트림을 종료하고, 더 이상의 연산자를 추가할 수 없다.
1) collect
지금까지 써왔던 연산자로 Flow의 모든 값을 수집하고 처리한다.
fun main() = runBlocking {
(1..3).asFlow().collect { value ->
println(value)
}
}
// <출력>
// 1
// 2
// 3
2) toList와 toSet
List나 Set 형태로 만들 수 있다.
fun main() = runBlocking {
(1..6).asFlow()
.toList()
.also {
print(it)
}
}
// <출력>
// [1,2,3,4,5,6]
3) first와 single
첫 데이터를 흘려보내주는 최종 연산자이다.
fun main() = runBlocking {
(1..6).asFlow()
.first()
.also {
print(it)
}
}
// <출력>
// 1
single의 경우는 특이하게 하나의 데이터만 흘러나올 때 실행해주고, 그 외에는 Exception 처리를 한다.
fun main() = runBlocking {
(1..6).asFlow()
.first()
.singleOrNull {
if(it == null) println("no single")
else println("single")
}
}
// <출력>
// 1
4) launchIn 및 onEach
launchIn의 경우 데이터를 수집하는 걸 지정한 CoroutineScope에서 새로운 코루틴을 시작하도록 하기 때문에 비동기적으로 수집할 수 있게 해준다.
collect와 동일한 역할을 하지만 collect는 호출한 코루틴 내에서 데이터를 수집하고, 모든 값이 수집될 때까지 코루틴을 블로킹한다.
반면 launchIn의 경우 지정한 CoroutineScope에서 비동기적으로 시작하고, 수집이 계속되는 동안 다른 작업과 병렬로 실행할 수있다.
나의 경우 collect 보다는 launchIn을 많이 사용하는데 일단 코드가 간결하고 Job 객체를 반환하기 때문에 예외 처리에 있어서도 유용하다.
비교한 표는 다음과 같다.
| 종류 | 종단 연산자(collect) | 종단 연산자(launchIn) |
| 실행 방식 | 동기적 | 비동기적 |
| 반환 타입 | Unit | Job |
| 사용 패턴 | 직접적인 수집 작업 구현 | Flow 연산자 체인과 함께 사용, 별도의 코루틴 관리가 필요함 |
| 취소 방법 | 호출한 코루틴을 취소 | 반환된 Job을 사용해 취소 |
| 에러 처리 | try-catch 블록 또는 collect 내부에서 처리 가능 | Flow 연산자 체인 내에서 catch 사용 |
| 수명 주기 관리 | 호출한 코루틴의 수명 주기에 종속 | 지정된 CoroutineScope의 수명 주기에 종속 |
| 코드 구조 및 가독성 | 명시적 수집 블록 내에서 로직 구현 | 연산자 체인과 함께 간결하게 사용 가능 |
| 적용 사례 | Flow를 동기적으로 수집해 후속 작업을 수행하고자 할 때 | Flow를 백그라운드에서 비동기적으로 수집하고, 메인 코루틴과 병행해 실행할 때 |
public fun <T> Flow<T>.launchIn(
scope: CoroutineScope
): Job
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
fun main() = runBlocking {
val numberFlow = flow {
for (i in 1..5) {
delay(100)
if (i == 3) throw IllegalArgumentException("예외 발생: 3은 처리할 수 없습니다")
emit(i)
}
}
numberFlow
.onEach { value ->
println("수집된 값: $value")
}
.catch { e ->
println("에러 발생: ${e.message}")
}
.launchIn(this)
println("Flow가 launchIn을 통해 시작되었습니다.")
delay(600) // Flow 수집이 완료될 때까지 대기
println("Main 코루틴 종료")
}
백프레셔 및 버퍼링
비동기 데이터 스트림을 처리할 때, 데이터 생산 속도와 소비 속도 간의 불일치 문제를 백프레셔(backpressure)라고 한다. 생산자가 너무 빨리 데이터를 생산하면 소비자가 이를 따라잡지 못해 메모리 사용량이 증가하거나 시스템 성능이 저하될 수 있다.
Flow에서의 백프레셔 관리 방법
Flow는 기본적으로 콜드 스트림으로, 소비자가 데이터를 처리할 준비가 되어 있을 때만 데이터를 방출한다. 하지만, 추가적인 백프레셔 관리가 필요한 경우, buffer, conflate, collectLatest 등의 연산자를 사용할 수 있다.
버퍼링 연산자
1) buffer
생산자와 소비자 간의 버퍼를 설정해 백프레셔를 관리한다.
fun fastFlow(): Flow<Int> = flow {
for (i in 1..5) {
emit(i)
delay(50) // 빠른 생산 속도
}
}
fun main() = runBlocking {
fastFlow()
.buffer(100) // 버퍼 크기 설정
.collect { value ->
delay(100) // 느린 소비 속도
println(value)
}
}
// <출력>
// Collected: 1
// Collected: 2
// Collected: 3
// Collected: 4
// Collected: 5
fastFlow에서는 50ms 간격으로 방출하는데, 100ms 간격으로 값을 소비한다. 이때 buffer(100)을 사용해 버퍼 크기를 설정함으로, 소비자가 생산 속도를 따라잡지 못해도 데이터가 손실되지 않도록 한다.
2) conflate
소비자가 가장 최근의 데이터를 받을 수 있도록, 지연되는 데이터는 무시하고 최근의 데이터를 흘려보내는 역할을 한다. collectLatest와 비슷한 역할이다.
fun simpleFlow() = flow<Int> {
for(i in 1..3){
delay(100)
emit(i)
}
}
fun main() = runBlocking {
simpleFlow()
.conflate()
.collect{ value ->
delay(300)
println(value)
}
}
// <출력>
// 1
// 3
Flow 결합
여러 개의 데이터 스트림을 결합해 복잡한 데이터의 처리를 가능하게 하는 결합 연산자들을 제공한다.
1) zip
두 개의 flow를 병렬로 결합해 짝을 이루는 값들을 함께 처리한다는 데 코드를 보면 이해가 빠르다.
val flow1 = flowOf(1, 2, 3)
val flow2 = flowOf("A", "B", "C")
fun main() = runBlocking {
flow1.zip(flow2) { a, b -> "$a$b" }
.collect { value -> println(value) }
}
// <출력>
// 1A
// 2B
// 3C
2) combine
두 개의 Flow를 결합해 최신 값을 함께 처리한다.
val flow1 = flowOf(1, 2, 3).onEach { delay(100) }
val flow2 = flowOf("A", "B", "C").onEach { delay(150) }
fun main() = runBlocking {
flow1.combine(flow2) { a, b -> "$a$b" }
.collect { value -> println(value) }
}
// <출력>
// 1A
// 2A
// 2B
// 3B
// 3C
flow1의 생산 속도가 flow2 보다 빠르기 때문에, 계속 데이터를 생산할 수록 그에 맞춰 결합을 시키는 방식으로 수집한다.
즉 zip의 경우는 두 개의 데이터가 준비 되어있을 때 결합이 이루어지지만, combine은 하나만 준비가 되어도 동작이 이루어지도록 한다.
3) flatMapConcat
concat은 여러 개의 플로우를 순차적으로 결합해 단일 플로우로 변환하는데 사용된다. 즉, 하나의 플로우가 완료된 후에 다음 플로우를 시작함으로, 데이터 스트림을 순차적으로 처리할 수 있도록 해준다. 이 부분이 이해가 잘 안되는데 코드를 보면서 하면 이해가 빠르다.
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
fun main() = runBlocking {
// 상위 플로우: 1부터 3까지의 숫자 방출
val upperFlow = flow {
for (i in 1..3) {
delay(100) // 각 숫자 사이에 딜레이
emit(i)
}
}
// flatMapConcat을 사용하여 각 숫자에 대한 하위 플로우 생성
val concatenatedFlow = upperFlow.flatMapConcat { number ->
flow {
emit("Start processing $number")
delay(200) // 하위 플로우 작업 시뮬레이션
emit("Finished processing $number")
}
}
// 최종적으로 플로우 수집
concatenatedFlow.collect { value ->
println(value)
}
}
// <출력>
// Start processing 1
// Finished processing 1
// Start processing 2
// Finished processing 2
// Start processing 3
// Finished processing 3
upperFlow라는 플로우를 만든 뒤, 이 플로우의 각 숫자에 대한 하위 플로우를 생성한다.
하위 플로우에서는 이를 가공해 새로운 데이터가 흐를 수 있도록 처리한다.
얘와 비슷한 역할을 하는 것 중에 flatMapMerge와 flatMapLatest가 있는데 얘네를 표로 정리해보면 다음과 같다.
| flatMapConcat | 상위 플로우의 각 요소에 대해 하위 플로우를 순차적으로 실행해 결합 | 하위 플로우가 완료된 후에 다음 하위 플로우를 실행한다. |
| flatMapMerge | 상위 플로우의 각 요소에 대해 하위 플로우를 동시에 실행해 병합한다. | 하위 플로우들이 병렬로 실행되며, 결과가 비순차적으로 방출될 수 있다. |
| flatMapLatest | 상위 플로우의 새로운 요소가 방출될 때마다 이전 하위 플로우를 취소하고 최신 하위 플로우를 실행한다. | 항상 최신의 하위 플로우만을 실행하여 이전 결과는 무시한다. |
일단 여기까지 정리하고, exception 처리 SharedFlow나 StateFlow에 대한 내용은 다음 글에서 정리해보겠다.
'Language > kotlin' 카테고리의 다른 글
| [Kotlin] Channel (3) | 2024.11.07 |
|---|---|
| [Kotlin] StateFlow 및 SharedFlow (2) | 2024.10.07 |
| [Kotlin] 고차 함수와 람다 표현식 (0) | 2024.08.10 |
| [Kotlin] object와 companion object의 초기화 시점 (0) | 2024.08.09 |
| [Kotlin] lateinit & lazy (0) | 2024.08.08 |